Week-6 (Matrix Chain Order / LCS)
CE100 Algorithms and Programming II¶
Week-6 (Matrix Chain Order / LCS)¶
Spring Semester, 2021-2022¶
Download DOC-PDF, DOC-DOCX, SLIDE, PPTX
Matrix Chain Order / Longest Common Subsequence¶
Outline¶
- Elements of Dynamic Programming
- Optimal Substructure
- Overlapping Subproblems
- Recursive Matrix Chain Order Memoization
- Top-Down Approach
- RMC
- MemoizedMatrixChain
- LookupC
- Dynamic Programming vs Memoization Summary
- Dynamic Programming
- Problem-2 : Longest Common Subsequence
- Definitions
- LCS Problem
- Notations
- Optimal Substructure of LCS
- Proof Case-1
- Proof Case-2
- Proof Case-3
- A recursive solution to subproblems (inefficient)
- Computing the length of and LCS
- LCS Data Structure for DP
- Bottom-Up Computation
- Constructing and LCS
- PRINT-LCS
- Back-pointer space optimization for LCS length
- Most Common Dynamic Programming Interview Questions
Elements of Dynamic Programming¶
- When should we look for a DP solution to an optimization problem?
- Two key ingredients for the problem
- Optimal substructure
- Overlapping subproblems
DP Hallmark #1¶
- Optimal Substructure
- A problem exhibits optimal substructure
- if an optimal solution to a problem contains within it optimal solutions to subproblems
- Example: matrix-chain-multiplication
- Optimal parenthesization of \(A_1 A_2 \dots A_n\) that splits the product between \(A_k\) and \(A_{k+1}\), contains within it optimal soln’s to the problems of parenthesizing \(A_1A_2 \dots A_k\) and \(A_{k+1} A_{k+2} \dots A_n\)
Optimal Substructure¶
- Finding a suitable space of subproblems
- Iterate on subproblem instances
- Example: matrix-chain-multiplication
- Iterate and look at the structure of optimal soln’s to subproblems, sub-subproblems, and so forth
- Discover that all subproblems consists of subchains of \(\langle A_1, A_2, \dots , A_n \rangle\)
- Thus, the set of chains of the form \(\langle A_i,A_{i+1}, \dots , A_j \rangle\) for \(1 \leq i \leq j \leq n\)
- Makes a natural and reasonable space of subproblems
DP Hallmark #2¶
- Overlapping Subproblems
- Total number of distinct subproblems should be polynomial in the input size
- When a recursive algorithm revisits the same problem over and over again,
- We say that the optimization problem has overlapping subproblems
Overlapping Subproblems¶
- DP algorithms typically take advantage of overlapping subproblems
- by solving each problem once
- then storing the solutions in a table
- where it can be looked up when needed
- using constant time per lookup
Overlapping Subproblems¶
- Recursive matrix-chain order
Direct Recursion: Inefficient!¶
- Recursion tree for \(RMC(p,1,4)\)
- Nodes are labeled with \(i\) and \(j\) values

Running Time of RMC¶
\(T(1) \geq 1\) \(T(n) \geq 1 + \sum \limits_{k=1}^{n-1} (T(k)+T(n-k)+1)\ \text{for} \ n>1\)
- For \(i =1,2, \dots ,n\) each term \(T(i)\) appears twice
- Once as \(T(k)\), and once as \(T(n-k)\)
- Collect \(n-1,\) \(1\)’s in the summation together with the front \(1\)
- Prove that \(T(n)= \Omega(2n)\) using the substitution method
Running Time of RMC: Prove that \(T(n)= \Omega(2n)\)¶
- Try to show that \(T(n) \geq 2^{n-1}\) (by substitution)
- Base case: \(T(1) \geq 1 = 2^0 = 2^{1-1}\) for \(n=1\)
- Ind. Hyp.:
Running Time of RMC: \(T(n) \geq 2^{n-1}\)¶
- Whenever
- a recursion tree for the natural recursive solution to a problem contains the same subproblem repeatedly
- the total number of different subproblems is small
- it is a good idea to see if \(DP (Dynamic \ Programming)\) can be applied
Memoization¶
- Offers the efficiency of the usual \(DP\) approach while maintaining top-down strategy
- Idea is to memoize the natural, but inefficient, recursive algorithm
Memoized Recursive Algorithm¶
- Maintains an entry in a table for the soln to each subproblem
- Each table entry contains a special value to indicate that the entry has yet to be filled in
- When the subproblem is first encountered its solution is computed and then stored in the table
- Each subsequent time that the subproblem encountered the value stored in the table is simply looked up and returned
Memoized Recursive Matrix-chain Order¶
- Shaded subtrees are looked-up rather than recomputing
Memoized Recursive Algorithm¶
- The approach assumes that
- The set of all possible subproblem parameters are known
- The relation between the table positions and subproblems is established
- Another approach is to memoize
- by using hashing with subproblem parameters as key
Dynamic Programming vs Memoization Summary (1)¶
- Matrix-chain multiplication can be solved in \(O(n^3)\) time
- by either a top-down memoized recursive algorithm
- or a bottom-up dynamic programming algorithm
- Both methods exploit the overlapping subproblems property
- There are only \(\Theta(n^2)\) different subproblems in total
- Both methods compute the soln to each problem once
- Without memoization the natural recursive algorithm runs in exponential time since subproblems are solved repeatedly
Dynamic Programming vs Memoization Summary (2)¶
- In general practice
- If all subproblems must be solved at once
- a bottom-up DP algorithm always outperforms a top-down memoized algorithm by a constant factor
- because, bottom-up DP algorithm
- Has no overhead for recursion
- Less overhead for maintaining the table
- DP: Regular pattern of table accesses can be exploited to reduce the time and/or space requirements even further
- Memoized: If some problems need not be solved at all, it has the advantage of avoiding solutions to those subproblems
Problem 3: Longest Common Subsequence¶
Definitions
-
A subsequence of a given sequence is just the given sequence with some elements (possibly none) left out
-
Example:
-
\(X = \langle A, B, C, B, D, A, B \rangle\)
- \(Z = \langle B, C, D, B \rangle\)
- \(Z\) is a subsequence of \(X\)
Problem 3: Longest Common Subsequence¶
Definitions
-
Formal definition: Given a sequence \(X = \langle x_1, x_2, \dots , x_m \rangle\), sequence \(Z = \langle z_1, z_2, \dots, z_k \rangle\) is a subsequence of \(X\)
-
if \(\exists\) a strictly increasing sequence \(\langle i_1, i_2,\dots, i_k \rangle\) of indices of \(X\) such that \(x_{i_j} = z_j\) for all \(j = 1, 2, …, k\), where \(1 \leq k \leq m\)
-
Example: \(Z = \langle B,C,D,B \rangle\) is a subsequence of \(X = \langle A,B,C,B,D,A,B \rangle\) with the index sequence \(\langle i_1, i_2, i_3, i_4 \rangle = \langle 2, 3, 5, 7 \rangle\)
Problem 3: Longest Common Subsequence¶
Definitions
-
If \(Z\) is a subsequence of both \(X\) and \(Y\), we denote \(Z\) as a common subsequence of \(X\) and \(Y\).
-
Example:
- \(Z_1 = \langle B^*, C^*, A^* \rangle\) is a common subsequence (of length 3) of \(X\) and \(Y\).
- Two longest common subsequence (LCSs) of \(X\) and \(Y\)?
- \(Z2 = \langle B, C, B, A \rangle\) of length \(4\)
- \(Z3 = \langle B, D, A, B \rangle\) of length \(4\)
- The optimal solution value = 4
Longest Common Subsequence (LCS) Problem¶
- LCS problem: Given two sequences
- \(X = \langle x_1, x_2, \dots, x_m \rangle\) and
- \(Y = \langle y_1, y_2, \dots , y_n \rangle\), find the LCS of \(X \& Y\)
- Brute force approach:
- Enumerate all subsequences of \(X\)
- Check if each subsequence is also a subsequence of \(Y\)
- Keep track of the LCS
- What is the complexity?
- There are \(2^m\) subsequences of \(X\)
- Exponential runtime
Notation¶
- Notation: Let \(X_i\) denote the \(i^{th}\) prefix of \(X\)
- i.e. \(X_i = \langle x_1, x_2, \dots, x_i \rangle\)
- Example:
Optimal Substructure of an LCS¶
- Let \(X = <x1, x2, …, xm>\) and \(Y = \langle y_1, y_2, \dots, y_n \rangle\) are given
- Let \(Z = \langle z_1, z_2, \dots, z_k \rangle\) be an LCS of \(X\) and \(Y\)

- Question 1: If \(x_m = y_n\), how to define the optimal substructure?
- We must have \(z_k = x_m = y_n\) and
- \(Z_{k-1} = \text{LCS}(X_{m-1}, Y_{n-1})\)
Optimal Substructure of an LCS¶
- Let \(X = <x1, x2, …, xm>\) and \(Y = \langle y_1, y_2, \dots, y_n \rangle\) are given
- Let \(Z = \langle z_1, z_2, \dots, z_k \rangle\) be an LCS of \(X\) and \(Y\)
- Question 2: If \(x_m \neq y_n \ \text{and} \ z_k \neq x_m\), how to define the optimal substructure?
- We must have \(Z = \text{LCS}(X_{m-1}, Y)\)
Optimal Substructure of an LCS¶
- Let \(X = <x1, x2, …, xm>\) and \(Y = \langle y_1, y_2, \dots, y_n \rangle\) are given
- Let \(Z = \langle z_1, z_2, \dots, z_k \rangle\) be an LCS of \(X\) and \(Y\)
- Question 3: If \(x_m \neq y_n \ \text{and} \ z_k \neq y_n\), how to define the optimal substructure?
- We must have \(Z = \text{LCS}(X, Y_{n-1})\)
Theorem: Optimal Substructure of an LCS¶
- Let \(X = \langle x_1, x_2, \dots, x_m \rangle\) and Y =
- Let \(Z = \langle z_1, z_2, \dots, z_k \rangle\) be an LCS of \(X\) and \(Y\)
- Theorem: Optimal substructure of an LCS:
- If \(x_m = y_n\)
- then \(z_k = x_m = y_n\) and \(Z_{k-1}\) is an LCS of \(X_{m-1}\) and \(Y_{n-1}\)
- If \(x_m \neq y_n\) and \(z_k \neq x_m\)
- then \(Z\) is an LCS of \(X_{m-1}\) and \(Y\)
- If \(x_m \neq y_n\) and \(z_k \neq y_n\)
- then \(Z\) is an LCS of \(X\) and \(Y_{n-1}\)
Optimal Substructure Theorem (case 1)¶
- If \(x_m = y_n\) then \(z_k = x_m = y_n\) and \(Z_{k-1}\) is an LCS of \(X_{m-1}\) and \(Y_{n-1}\)

Optimal Substructure Theorem (case 2)¶
- If \(x_m \neq y_n\) and \(z_k \neq x_m\) then \(Z\) is an LCS of \(X_{m-1}\) and \(Y\)

Optimal Substructure Theorem (case 3)¶
- If \(x_m \neq y_n\) and \(z_k \neq y_n\) then \(Z\) is an LCS of \(X\) and \(Y_{n-1}\)

Proof of Optimal Substructure Theorem (case 1)¶
- If \(x_m = y_n\) then \(z_k = x_m = y_n\) and \(Z_{k-1}\) is an LCS of \(X_{m-1}\) and \(Y_{n-1}\)
- Proof: If \(z_k \neq x_m = y_n\) then
- we can append \(x_m = y_n\) to \(Z\) to obtain a common subsequence of length \(k+1 \Longrightarrow\) contradiction
- Thus, we must have \(z_k = x_m = y_n\)
- Hence, the prefix \(Z_{k-1}\) is a length-(\(k-1\)) CS of \(X_{m-1}\) and \(Y_{n-1}\)
- We have to show that \(Z_{k-1}\) is in fact an LCS of \(X_{m-1}\) and \(Y_{n-1}\)
- Proof by contradiction:
- Assume that \(\exists\) a CS \(W\) of \(X_{m-1}\) and \(Y_{n-1}\) with \(|W| = k\)
- Then appending \(x_m = y_n\) to \(W\) produces a CS of length \(k+1\)
Proof of Optimal Substructure Theorem (case 2)¶
- If \(x_m \neq y_n\) and \(z_k \neq x_m\) then \(Z\) is an LCS of \(X_{m-1}\) and \(Y\)
- Proof : If \(z_k \neq x_m\) then \(Z\) is a CS of \(X_{m-1}\) and \(Y_n\)
- We have to show that \(Z\) is in fact an LCS of \(X_{m-1}\) and \(Y_n\)
- (Proof by contradiction)
- Assume that \(\exists\) a CS \(W\) of \(X_{m-1}\) and \(Y_n\) with \(|W| > k\)
- Then \(W\) would also be a CS of \(X\) and \(Y\)
- Contradiction to the assumption that
- \(Z\) is an LCS of \(X\) and \(Y\) with \(|Z| = k\)
- Case 3: Dual of the proof for (case 2)
A Recursive Solution to Subproblems¶
- Theorem implies that there are one or two subproblems to examine
- if \(x_m = y_n\) then
- we must solve the subproblem of finding an LCS of \(X_{m-1} \& Y_{n-1}\)
- appending \(x_m = y_n\) to this LCS yields an LCS of \(X \& Y\)
- else
- we must solve two subproblems
- finding an LCS of \(X_{m-1} \& Y\)
- finding an LCS of \(X \& Y_{n-1}\)
- longer of these two LCS s is an LCS of \(X \& Y\)
- endif
Recursive Algorithm (Inefficient)¶
A Recursive Solution¶
- \(c[i, j]:\) length of an LCS of \(X_i\) and \(Y_j\)
Computing the Length of an LCS¶
- We can easily write an exponential-time recursive algorithm based on the given recurrence. \(\Longrightarrow\) Inefficient!
- How many distinct subproblems to solve?
- \(\Theta(mn)\)
- Overlapping subproblems property: Many subproblems share the same sub-subproblems.
- e.g. Finding an LCS to \(X_{m-1} \& Y\) and an LCS to \(X \& Y_{n-1}\)
- has the sub-subproblem of finding an LCS to \(X_{m-1} \& Y_{n-1}\)
- Therefore, we can use dynamic programming.
Data Structures¶
- Let:
- \(c[i, j]:\) length of an LCS of \(X_i\) and \(Y_j\)
- \(b[i, j]:\) direction towards the table entry corresponding to the optimal subproblem solution chosen when computing \(c[i, j]\).
- Used to simplify the construction of an optimal solution at the end.
- Maintain the following tables:
- \(c[0 \dots m, 0 \dots n]\)
- \(b[1 \dots m, 1 \dots n]\)
Bottom-up Computation¶
- Reminder:
- How to choose the order in which we process \(c[i, j]\) values?
- The values for \(c[i-1, j-1]\), \(c[i, j-1]\), and \(c[i-1,j]\) must be computed before computing \(c[i, j]\).
Bottom-up Computation¶
Need to process:
\(c[i, j]\)
after computing:
\(c[i-1, j-1]\),
\(c[i, j-1]\),
\(c[i-1,j]\)

Bottom-up Computation¶

Computing the Length of an LCS¶
Computing the Length of an LCS-1¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-2¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-3¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-4¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-5¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-6¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-7¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-8¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-9¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-10¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-11¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-12¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$

Computing the Length of an LCS-13¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$
- Running-time = \(O(mn)\) since each table entry takes \(O(1)\) time to compute

Computing the Length of an LCS-14¶
Operation of LCS-LENGTH on the sequences $$ \begin{align*} X &= \langle \overset{1}{A}, \overset{2}{B}, \overset{3}{C}, \overset{4}{B}, \overset{5}{D}, \overset{6}{A}, \overset{7}{B} \rangle \ Y &= \langle \overset{1}{B}, \overset{2}{D}, \overset{3}{C}, \overset{4}{A}, \overset{5}{B}, \overset{6}{A} \rangle \end{align*} $$
-
Running-time = \(O(mn)\) since each table entry takes \(O(1)\) time to compute
-
LCS of \(X \& Y = \langle B, C, B, A \rangle\)

Constructing an LCS¶
- The \(b\) table returned by LCS-LENGTH can be used to quickly construct an LCS of \(X \& Y\)
- Begin at \(b[m, n]\) and trace through the table following arrows
- Whenever you encounter a "\(\nwarrow\)" in entry \(b[i, j]\) it implies that \(x_i = y_j\) is an element of LCS
- The elements of LCS are encountered in reverse order
Constructing an LCS¶
- The recursive procedure \(\text{PRINT-LCS}\) prints out \(\text{LCS}\) in proper order
- This procedure takes \(O(m+n)\) time since at least one of \(i\) and \(j\) is decremented in each stage of the recursion
- The initial invocation: \(\text{PRINT-LCS}(b, X, length[X], length[Y])\)
Do we really need the b table (back-pointers)?¶
- Question: From which neighbor did we expand to the highlighted cell?
- Answer: Upper-left neighbor,because \(X[i] = Y[j]\).

Do we really need the b table (back-pointers)?¶
- Question: From which neighbor did we expand to the highlighted cell?
- Answer: Left neighbor, because \(X[i] \neq Y[j]\) and \(LCS[i, j-1] > LCS[i-1, j]\).

Do we really need the b table (back-pointers)?¶
- Question: From which neighbor did we expand to the highlighted cell?
- Answer: Upper neighbor,because \(X[i] \neq Y[j]\) and \(LCS[i, j-1] = LCS[i-1, j]\). (See pseudo-code to see how ties are handled.)

Improving the Space Requirements¶
- We can eliminate the b table altogether
- each \(c[i, j]\) entry depends only on \(3\) other \(c\) table entries: \(c[i-1, j-1]\), \(c[i-1, j]\) and \(c[i, j-1]\)
- Given the value of \(c[i, j]\):
- We can determine in \(O(1)\) time which of these \(3\) values was used to compute \(c[i, j]\) without inspecting table \(b\)
- We save \(\Theta(mn)\) space by this method
- However, space requirement is still \(\Theta(mn)\) since we need \(\Theta(mn)\) space for the \(c\) table anyway
What if we store the last 2 rows only?¶
- To compute \(c[i, j]\), we only need \(c[i-1, j-1]\), \(c[i-1, j]\),and \(c[i-1, j-1]\)
- So, we can store only the last two rows.

What if we store the last 2 rows only?¶
- To compute \(c[i, j]\), we only need \(c[i-1, j-1]\), \(c[i-1, j]\), and \(c[i-1, j-1]\)
- So, we can store only the last two rows.

What if we store the last 2 rows only?¶
-
To compute \(c[i, j]\), we only need \(c[i-1, j-1]\), \(c[i-1, j]\), and \(c[i-1, j-1]\)
-
So, we can store only the last two rows.
-
This reduces space complexity from \(\Theta(mn)\) to \(\Theta(n)\).
-
Is there a problem with this approach?

What if we store the last 2 rows only?¶
-
Is there a problem with this approach?
-
We cannot construct the optimal solution because we cannot backtrace anymore.
- This approach works if we only need the length of an LCS, not the actual LCS.
Problem 4 Optimal Binary Search Tree¶
Reminder: Binary Search Tree (BST)¶

Binary Search Tree Example¶
- Example: English-to-French translation
- Organize (English, French) word pairs in a BST
- Keyword: English word
- Satellite Data: French word
- We can search for an English word (node key) efficiently, and return the corresponding French word (satellite data).

ASCII Table¶

Binary Search Tree Example¶
Suppose we know the frequency of each keyword in texts: $$ \underset{5\%}{\underline{begin}}, \underset{40\%}{\underline{do}}, \underset{8\%}{\underline{else}}, \underset{4\%}{\underline{end}}, \underset{10\%}{\underline{if}}, \underset{10\%}{\underline{then}}, \underset{23\%}{\underline{while}}, $$

Cost of a Binary Search Tree¶
Example: If we search for keyword "while", we need to access \(3\) nodes. So, \(23%\) of the queries will have cost of \(3\).
Cost of a Binary Search Tree¶
Example: If we search for keyword "while", we need to access \(3\) nodes. So, \(23%\) of the queries will have cost of \(3\).
- This is in fact an optimal BST.

Optimal Binary Search Tree Problem¶
- Given:
- A collection of \(n\) keys \(K_1 < K_2 < \dots K_n\) to be stored in a BST.
- The corresponding \(p_i\) values for \(1 \leq i \leq n\)
- \(p_i\): probability of searching for key \(K_i\)
- Find:
- An optimal BST with minimum total cost:
- Note: The BST will be static. Only search operations will be performed. No insert, no delete, etc.
Cost of a Binary Search Tree¶
- Lemma 1: Let \(Tij\) be a BST containing keys \(K_i < K_{i+1} < \dots < K_j\). Let \(T_L\) and \(T_R\) be the left and right subtrees of \(T\). Then we have:
Intuition: When we add the root node, the depth of each node in \(T_L\) and \(T_R\) increases by \(1\). So, the cost of node \(h\) increases by \(p_h\). In addition, the cost of root node \(r\) is \(p_r\). That’s why, we have the last term at the end of the formula above.

Optimal Substructure Property¶
- Lemma 2: Optimal substructure property
- Consider an optimal BST \(T_{ij}\) for keys \(K_i < K_{i+1} < \dots < K_j\)
- Let \(K_m\) be the key at the root of \(T_{ij}\)
- Then:
- \(T_{i,m-1}\) is an optimal BST for subproblem containing keys:
- \(K_i < \dots < K_{m-1}\)
- \(T_{m+1,j}\) is an optimal BST for subproblem containing keys:
- \(K_{m+1} < \dots < K_j\)

Recursive Formulation¶
-
Note: We don’t know which root vertex leads to the minimum total cost. So, we need to try each vertex \(m\), and choose the one with minimum total cost.
-
\(c[i, j]\): cost of an optimal BST \(T_{ij}\) for the subproblem \(K_i < \dots < K_j\)
Bottom-up computation¶
- How to choose the order in which we process \(c[i, j]\) values?
- Before computing \(c[i, j]\), we have to make sure that the values for \(c[i, r-1]\) and \(c[r+1,j]\) have been computed for all \(r\).
Bottom-up computation¶
- \(c[i,j]\) must be processed after \(c[i,r-1]\) and \(c[r+1,j]\)

Bottom-up computation¶
- If the entries \(c[i,j]\) are computed in the shown order, then \(c[i,r-1]\) and \(c[r+1,j]\) values are guaranteed to be computed before \(c[i,j]\).

Computing the Optimal BST Cost¶
Note on Prefix Sum¶
- We need \(P_{ij}\) values for each \(i, j (1 ≤ i ≤ n \ \text{and} \ 1 ≤ j ≤ n)\), where:
-
If we compute the summation directly for every \((i, j)\) pair, the runtime would be \(\Theta(n^3)\).
-
Instead, we spend \(O(n)\) time in preprocessing to compute the prefix sum array PS. Then we can compute each \(P_{ij}\) in \(O(1)\) time using PS.
Note on Prefix Sum¶
- In preprocessing, compute for each \(i\):
- \(PS[i]\): the sum of \(p[j]\) values for \(1 \leq j \leq i\)
- Then, we can compute \(P_{ij}\) in \(O(1)\) time as follows:
- \(P_{ij} = PS[i] – PS[j-1]\)
- Example:
REVIEW¶
Overlapping Subproblems Property in Dynamic Programming¶
Dynamic Programming is an algorithmic paradigm that solves a given complex problem by breaking it into subproblems and stores the results of subproblems to avoid computing the same results again.
Overlapping Subproblems Property in Dynamic Programming¶
Following are the two main properties of a problem that suggests that the given problem can be solved using Dynamic programming.
- Overlapping Subproblems
- Optimal Substructure
Overlapping Subproblems¶
- Like Divide and Conquer, Dynamic Programming combines solutions to sub-problems.
- Dynamic Programming is mainly used when solutions of the same subproblems are needed again and again.
- In dynamic programming, computed solutions to subproblems are stored in a table so that these don’t have to be recomputed.
- So Dynamic Programming is not useful when there are no common (overlapping) subproblems because there is no point storing the solutions if they are not needed again.
Overlapping Subproblems¶
- For example, Binary Search doesn’t have common subproblems.
- If we take an example of following recursive program for Fibonacci Numbers, there are many subproblems that are solved again and again.
Simple Recursion¶
- \(f(n) = f(n-1) + f(n-2)\)
- C sample code:
#include <stdio.h>
// a simple recursive program to compute fibonacci numbers
int fib(int n)
{
if (n <= 1)
return n;
else
return fib(n-1) + fib(n-2);
}
int main()
{
int n = 5;
printf("Fibonacci number is %d ", fib(n));
return 0;
}
Simple Recursion¶
- Output
Simple Recursion¶
- \(f(n) = f(n-1) + f(n-2)\)
/* a simple recursive program for Fibonacci numbers */
public class Fibonacci {
public static void main(String[] args) {
int n = Integer.parseInt(args[0]);
System.out.println(fib(n));
}
public static int fib(int n) {
if (n <= 1)
return n;
return fib(n - 1) + fib(n - 2);
}
}
Simple Recursion¶
- \(f(n) = f(n-1) + f(n-2)\)
public class Fibonacci {
public static void Main(string[] args) {
int n = int.Parse(args[0]);
Console.WriteLine(fib(n));
}
public static int fib(int n) {
if (n <= 1)
return n;
return fib(n - 1) + fib(n - 2);
}
}
Recursion tree for execution of fib(5)¶
fib(5)
/ \
fib(4) fib(3)
/ \ / \
fib(3) fib(2) fib(2) fib(1)
/ \ / \ / \
fib(2) fib(1) fib(1) fib(0) fib(1) fib(0)
/ \
fib(1) fib(0)
- We can see that the function
fib(3)is being called 2 times. - If we would have stored the value of
fib(3), then instead of computing it again, we could have reused the old stored value.
Recursion tree for execution of fib(5)¶
There are following two different ways to store the values so that these values can be reused:
- Memoization (Top Down)
- Tabulation (Bottom Up)
Memoization (Top Down)¶
- The memoized program for a problem is similar to the recursive version with a small modification that looks into a lookup table before computing solutions.
- We initialize a lookup array with all initial values as
NIL. Whenever we need the solution to a subproblem, we first look into the lookup table. - If the precomputed value is there then we return that value, otherwise, we calculate the value and put the result in the lookup table so that it can be reused later.
Memoization (Top Down)¶
- Following is the memoized version for the nth Fibonacci Number.
- C++ Version:
/* C++ program for Memoized version
for nth Fibonacci number */
#include <bits/stdc++.h>
using namespace std;
#define NIL -1
#define MAX 100
int lookup[MAX];
Memoization (Top Down)¶
- C++ Version:
/* Function to initialize NIL
values in lookup table */
void _initialize()
{
int i;
for (i = 0; i < MAX; i++)
lookup[i] = NIL;
}
Memoization (Top Down)¶
- C++ Version:
/* function for nth Fibonacci number */
int fib(int n)
{
if (lookup[n] == NIL) {
if (n <= 1)
lookup[n] = n;
else
lookup[n] = fib(n - 1) + fib(n - 2);
}
return lookup[n];
}
Memoization (Top Down)¶
- C++ Version:
// Driver code
int main()
{
int n = 40;
_initialize();
cout << "Fibonacci number is " << fib(n);
return 0;
}
Memoization (Top Down)¶
- Java Version:
/* Java program for Memoized version */
public class Fibonacci {
final int MAX = 100;
final int NIL = -1;
int lookup[] = new int[MAX];
/* Function to initialize NIL values in lookup table */
void _initialize()
{
for (int i = 0; i < MAX; i++)
lookup[i] = NIL;
}
Memoization (Top Down)¶
- Java Version:
/* function for nth Fibonacci number */
int fib(int n)
{
if (lookup[n] == NIL) {
if (n <= 1)
lookup[n] = n;
else
lookup[n] = fib(n - 1) + fib(n - 2);
}
return lookup[n];
}
Memoization (Top Down)¶
- Java Version:
public static void main(String[] args)
{
Fibonacci f = new Fibonacci();
int n = 40;
f._initialize();
System.out.println("Fibonacci number is"
+ " " + f.fib(n));
}
}
Memoization (Top Down)¶
- C# Version:
// C# program for Memoized versionof nth Fibonacci number
using System;
class FiboCalcMemoized {
static int MAX = 100;
static int NIL = -1;
static int[] lookup = new int[MAX];
/* Function to initialize NIL
values in lookup table */
static void initialize()
{
for (int i = 0; i < MAX; i++)
lookup[i] = NIL;
}
Memoization (Top Down)¶
- C# Version:
/* function for nth Fibonacci number */
static int fib(int n)
{
if (lookup[n] == NIL) {
if (n <= 1)
lookup[n] = n;
else
lookup[n] = fib(n - 1) + fib(n - 2);
}
return lookup[n];
}
Memoization (Top Down)¶
- C# Version:
// Driver code
public static void Main()
{
int n = 40;
initialize();
Console.Write("Fibonacci number is"
+ " " + fib(n));
}
}
Tabulation (Bottom Up)¶
- The tabulated program for a given problem builds a table in bottom-up fashion and returns the last entry from the table.
- For example, for the same Fibonacci number,
- we first calculate
fib(0)thenfib(1)thenfib(2)thenfib(3), and so on. So literally, we are building the solutions of subproblems bottom-up.
Tabulation (Bottom Up)¶
- C++ Version:
/* C program for Tabulated version */
#include <stdio.h>
int fib(int n)
{
int f[n + 1];
int i;
f[0] = 0;
f[1] = 1;
for (i = 2; i <= n; i++)
f[i] = f[i - 1] + f[i - 2];
return f[n];
}
Tabulation (Bottom Up)¶
- C++ Version:
Output:
Tabulation (Bottom Up)¶
- Java Version:
/* Java program for Tabulated version */
public class Fibonacci {
public static void main(String[] args)
{
int n = 9;
System.out.println("Fibonacci number is " + fib(n));
}
Tabulation (Bottom Up)¶
- Java Version:
/* Function to calculate nth Fibonacci number */
static int fib(int n)
{
int f[] = new int[n + 1];
f[0] = 0;
f[1] = 1;
for (int i = 2; i <= n; i++)
f[i] = f[i - 1] + f[i - 2];
return f[n];
}
}
Tabulation (Bottom Up)¶
- C# Version:
// C# program for Tabulated version
using System;
class Fibonacci {
static int fib(int n)
{
int[] f = new int[n + 1];
f[0] = 0;
f[1] = 1;
for (int i = 2; i <= n; i++)
f[i] = f[i - 1] + f[i - 2];
return f[n];
}
public static void Main()
{
int n = 9;
Console.Write("Fibonacci number is"
+ " " + fib(n));
}
}
- Both Tabulated and Memoized store the solutions of subproblems.
- In Memoized version, the table is filled on demand while in the Tabulated version, starting from the first entry, all entries are filled one by one.
- Unlike the Tabulated version, all entries of the lookup table are not necessarily filled in Memoized version.
-
To see the optimization achieved by Memoized and Tabulated solutions over the basic Recursive solution, see the time taken by following runs for calculating the 40th Fibonacci number:
-
Recursive Solution:
-
Memoized Solution:
-
Tabulated Solution:
Optimal Substructure Property in Dynamic Programming¶
-
A given problems has Optimal Substructure Property if optimal solution of the given problem can be obtained by using optimal solutions of its subproblems.
-
For example, the Shortest Path problem has following optimal substructure property:
-
If a node x lies in the shortest path from a source node u to destination node v then the shortest path from u to v is combination of shortest path from u to x and shortest path from x to v. The standard All Pair Shortest Path algorithm like Floyd–Warshall and Single Source Shortest path algorithm for negative weight edges like Bellman–Ford are typical examples of Dynamic Programming.
Optimal Substructure Property in Dynamic Programming¶
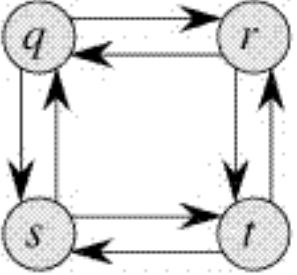
- On the other hand, the Longest Path problem doesn’t have the Optimal Substructure property. Here by Longest Path we mean longest simple path (path without cycle) between two nodes
Optimal Substructure Property in Dynamic Programming¶
- There are two longest paths from q to t: q→r→t and q→s→t. Unlike shortest paths, these longest paths do not have the optimal substructure property. For example, the longest path q→r→t is not a combination of longest path from q to r and longest path from r to t, because the longest path from q to r is q→s→t→r and the longest path from r to t is r→q→s→t.
Most Common Dynamic Programming Interview Questions¶
Problem-1: Longest Increasing Subsequence¶
Problem-1: Longest Increasing Subsequence¶
Problem-2: Edit Distance¶
Problem-2: Edit Distance (Recursive)¶
Problem-2: Edit Distance (DP)¶
https://www.coursera.org/learn/dna-sequencing
Problem-2: Edit Distance (DP)¶
Problem-2: Edit Distance (Other)¶
Problem-3: Partition a set into two subsets such that the difference of subset sums is minimum¶
Problem-4: Count number of ways to cover a distance¶
Problem-5: Find the longest path in a matrix with given constraints¶
Problem-6: Subset Sum Problem¶
Problem-7: Optimal Strategy for a Game¶
Problem-8: 0-1 Knapsack Problem¶
Problem-9: Boolean Parenthesization Problem¶
Problem-10: Shortest Common Supersequence¶
Problem-11: Partition Problem¶
Problem-12: Cutting a Rod¶
Problem-13: Coin Change¶
Problem-14: Word Break Problem¶
Problem-15: Maximum Product Cutting¶
Problem-16: Dice Throw¶
Problem-16: Dice Throw¶
Problem-17: Box Stacking Problem¶
Problem-18: Egg Dropping Puzzle¶
References¶
\(-End-Of-Week-6-Course-Module-\)